2021.07.26 TIL (Today I Learned)
TIL (Today I Learned)
BoostCamp Challenge DAY-6
- Study XML Parser, 컴파일러 이론
- Study Regular Expression
Study XML Parser
XML Parser
XML DOM은 XML 문서에 접근하고 조작할 수 있는 다양한 메소드를 포함하고 있다. XML 파서(parser)는 XML 문서의 평문(plain text) 데이터를 읽어 들여, 그것을 XML DOM 객체로 반환한다.
DOM(Document Object Model)은 XML이나 HTML 문서에 접근하기 위한 API로 W3C 표준 권고안이다. DOM은 문서 내의 모든 요소를 정의하고, 해당 요소에 접근하는 방법까지 정의한다. W3C DOM 표준은 다음과 같이 세 가지 모델로 구분된다.
- Core DOM : 모든 문서 타입을 위한 DOM 모델
- HTML DOM : HTML 문서를 위한 DOM 모델
- XML DOM : XML 문서를 위한 DOM 모델
컴파일러 이론
- 컴파일러(compiler) : src -> target (src ->obj)
- 문법 분석 (Sysntax Analysis) : src 언어를 이해하고 AST 생성
- 코드 생성 (Code Generation) : 문법을 통해 프로그램의 의미(sementics)를 찾고, AST를 대상 언어(target)로 번역
- 문법 분석 (Sysntax Analysis)
- Tokenizer : src를 언어 기본 요소들로 분류
- Lexer : 요소들의 의미를 분석 (Tokenizer + Lexer = Lexical Analysis, 어휘 분석)
- Parser : Tokenizing 결과로 AST 생성
AST(Abstract Syntax Tree) : 추상 구문 트리
예제
<?xml version="1.0" encoding="UTF-8"?>
<programming_languages>
<language>
<name>CSS</name>
<category>web</category>
<developer>W3C</developer>
<version status="stable">3.0</version>
<priority rating="3">high</priority>
</language>
</programming_languages>
const tokens = tokenizer(src);
const lexerTokens = lexer(tokens);
const parseTree = parser(lexerTokens);
Tokenizer
- 어떤 구문을 기본 요소들(Token)로 분리
[
...
, <programming_languages>
, <language>
...
, <version
, status
, =
, "stable"
, >
, 3.0
, </version>
, ...
]
Lexer
- Token의 의미를 분석
- Lexical Analysis (어휘 분석)
[
...
{
value : "<programming_languages>"
, identifier : programming_languages
, type : Tag.OPEN
, child : [...]
},
{
value : "<version"
, identifier : version
, type : Tag.OPEN
, child : []
},
{
value : "status"
, type : Attribute.NAME
, child : []
},
{
value : "="
, type : Operator.ASSIGN
, child : []
}
...
]
Parser
- Lexical Analysis 까지 완료된 Token들을 문법 규칙에 맞게 대응
- 계층적인 문법 규칙에 따라 AST 생성
type : root
chile : [
{
type : element
, value : programming_languages
, child : [
{
type : element
, value : language
, child : [
{
type : element
, value : name
, text : "CSS"
},
...
{
type : element
, value : version
, attribute : [
{ name : status, value : "stable"}
]
,text : "3.0"
}
...
]
}
]
}
]
결과 : XML 트리 (노드 트리, DOM 트리)
Study Regular Expression
- 정규 표현식
- 유용한 사이트
- https://regex101.com/
- https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec
실무에서의 사용
- 이메일, 주소, 전화번호 규칙 검증
- text area 입력값 중 불필요한 값 추출
- 트랜스파일링 (transpiling, ex. babel …)
- 개발도구에서의 문자열 치환
예제
const a = "<body>";
const b = "<body attr='value'>";
const c = "<br/>";
const d = "<br2 />";
a.match(/</);
a.match(/^<body/);
a.match(/^<body>/);
a.match(/^<body>?/);
a.match(/<^body>/)[0];
b.match(/^<body>/);
b.match(/^<body>?/);
c.match(/^<body>?/);
c.match(/^<[a-zA-Z]>?/);
c.match(/^<[a-zA-Z]+>?/);
a.match(/^<[a-zA-Z]>?/);
a.match(/^<[a-zA-Z]+>?/);
b.match(/^<[a-zA-Z]>?/);
b.match(/^<[a-zA-Z]+>?/);
c.match(/^<[a-zA-Z]+\/?>?/);
d.match(/^<[a-zA-Z][a-zA-Z\d]+\s*\/?>?/);
d.match(/^<([a-zA-Z][a-zA-Z\d]+)\s*\/?>?/);
b.match(/^<([a-zA-Z][a-zA-Z\d]+)\s*\/?>?/);
d.match(/^<([a-zA-Z][a-zA-Z\d]+)\s*\/?>?/)[1];
b.match(/^<([a-zA-Z][a-zA-Z\d]+)\s*\/?>?/)[1];
How to study Regex
javascript regex cheat sheet 패턴들을 테스트하면서 구현해보기
replace Method
- https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/String/replace
// 주석제거 <!DOCTYPE html>
const removeComment = (str) => str.replace(/(<!.*?>)/g, '');
😥 NOT DONE
- XPath
XPath란 XML Path Language를 의미한다. XPath는 XML 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어이다.
XPath는 W3C 표준 권고안으로, XSLT와 XPointer에 사용될 목적으로 만들어졌다. 또한, XML DOM에서 노드를 검색할 때에도 사용할 수 있다.
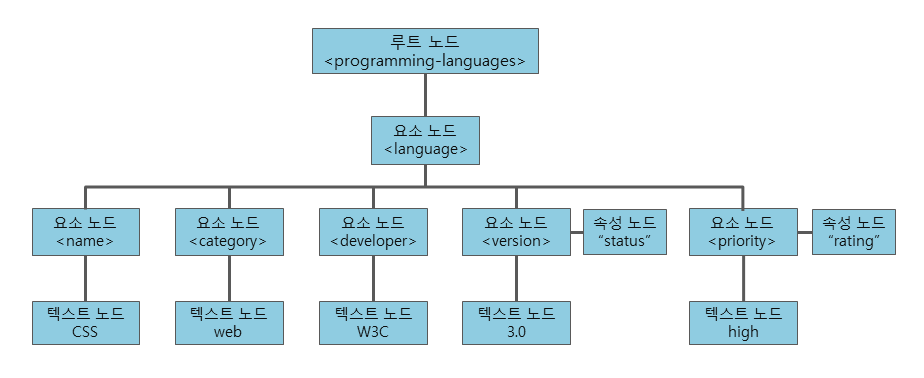
- XPath 노드의 형식
- 루트 노드
- 요소 노드
- 텍스트 노드
- 속성 노드
- 주석 노드
- 네임스페이스(namespace) 노드
- 처리 명령(processing instruction) 노드
- 탐욕적(greedy), 게으른(lazy) 수량자
- greedy : *, +, {n,}
- lazy : *?, +?, {n,}?
- backreference
Reference
- TCP School - XML
- https://chodragon9.github.io/blog/compiler-theory/#step-1-%EB%AC%B8%EB%B2%95-%EB%B6%84%EC%84%9D%EA%B8%B0-syntax-analyzer
- https://velog.io/@mu1616/%EC%BB%B4%ED%8C%8C%EC%9D%BC%EB%9F%AC-%EC%9D%B4%EB%A1%A0%EC%97%90%EC%84%9C-%ED%86%A0%ED%81%AC%EB%82%98%EC%9D%B4%EC%A0%80Tokenizer-%EB%A0%89%EC%84%9CLexer-%ED%8C%8C%EC%84%9CParse-%EC%9D%98-%EC%97%AD%ED%95%A0